We leverage large-scale pretrained VLMs via a three stage process:
1.) Prompt the VLM to decompose the original task into semantic sub-tasks, using the instruction and first frame for context.
2.) process the full trajectory video to identify temporal boundaries where each sub-task occurs.
3.) Generate diverse paraphrases for each sub-task instruction, grounded in the visual context. This creates richer descriptions incorporating object attributes and spatial relationships.
TREAD is a scalable framework for augmenting existing robotics datasets into more granular language-action segments, effectively increasing the diversity of our training data without requiring additional data collection.
The recent trend in scaling models for robot learning has resulted in impressive policies that can perform various manipulation tasks and generalize to novel scenarios. However, these policies continue to struggle with following instructions, likely due to the limited linguistic and action sequence diversity in existing robotics datasets.
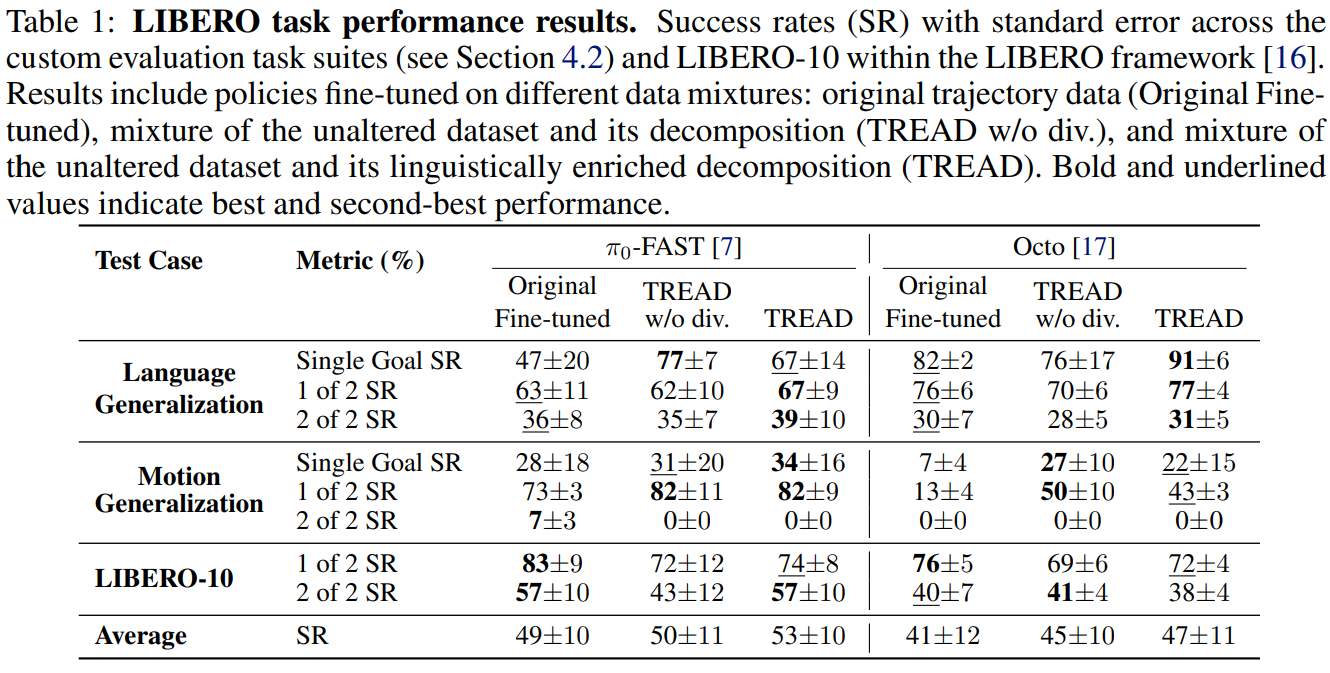
This paper introduces Task Robustness via RE-Labelling Vision-Action Robot Data (TREAD), a scalable framework that leverages large Vision-Language Models (VLMs) to augment existing robotics datasets without additional data collection, harnessing the transferable knowledge embedded in these models. Our approach leverages a pretrained VLM through three stages: generating semantic sub-tasks from original instruction labels and initial scenes, segmenting demonstration videos conditioned on these sub-tasks, and producing diverse instructions that incorporate object properties, effectively decomposing longer demonstrations into grounded language-action pairs. We further enhance robustness by augmenting the data with linguistically diverse versions of the text goals. Evaluations on LIBERO demonstrate that policies trained on our augmented datasets exhibit improved performance on novel, unseen tasks and goals. Our results show that TREAD enhances both planning generalization through trajectory decomposition and languageconditioned policy generalization through increased linguistic diversity.
@inproceedings{
kuramshin2025task,
title={Task Robustness via Re-Labelling Vision-Action Robot Data},
author={Artur Kuramshin and Ozgur Aslan and Cyrus Neary and Glen Berseth},
booktitle={Workshop on Making Sense of Data in Robotics: Composition, Curation, and Interpretability at Scale at CoRL 2025},
year={2025},
url={https://openreview.net/forum?id=M6M5W0lmaY}
}